
{kind=link}
Previous posts: https://programming.dev/post/3974121 and https://programming.dev/post/3974080
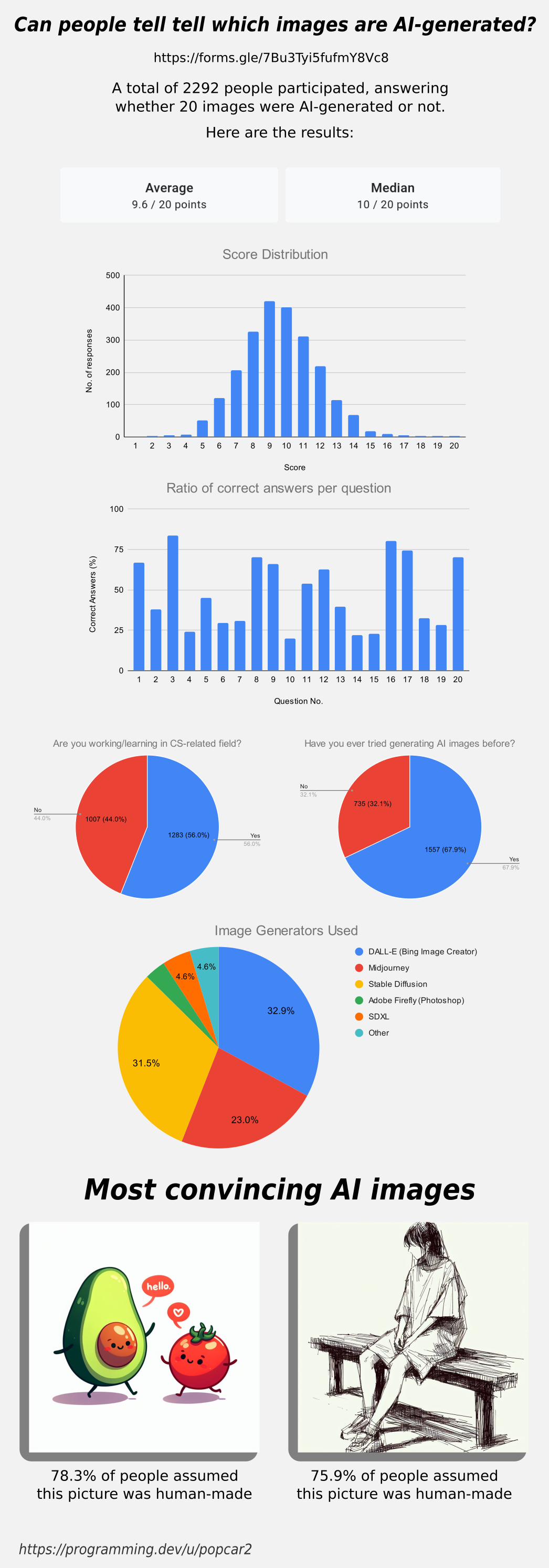
Original survey link: https://forms.gle/7Bu3Tyi5fufmY8Vc8
Thanks for all the answers, here are the results for the survey in case you were wondering how you did!
Edit: People working in CS or a related field have a 9.59 avg score while the people that aren’t have a 9.61 avg.
People that have used AI image generators before got a 9.70 avg, while people that haven’t have a 9.39 avg score.
Edit 2: The data has slightly changed! Over 1,000 people have submitted results since posting this image, check the dataset to see live results. Be aware that many people saw the image and comments before submitting, so they’ve gotten spoiled on some results, which may be leading to a higher average recently: https://docs.google.com/spreadsheets/d/1MkuZG2MiGj-77PGkuCAM3Btb1_Lb4TFEx8tTZKiOoYI
But they were generated by AI. It’s a fair definition
I mean fair, I just think that kind of thing stretches the definition of “fooling people”
LLMs are never divorced from human interaction or curation. They are trained by people from the start, so personal curation seems like a weird caveat to get hung up on with this study. The AI is simply a tool that is being used by people to fool people.
To take it to another level on the artistic spectrum, you could get a talented artist to make pencil drawings to mimic oil paintings, then mix them in with actual oil paintings. Now ask a bunch of people which ones are the real oil paintings and record the results. The human interaction is what made the pencil look like an oil painting, but that doesn’t change the fact that the pencil generated drawings could fool people into thinking they were an oil painting.
AIs like the ones used in this study are artistic tools that require very little actual artistic talent to utilize, but just like any other artistic tool, they fundamentally need human interaction to operate.
But not all AI generated images can fool people the way this post suggests. In essence this study then has a huge selection bias, which just makes it unfit for drawing any kind of conclusion.
This is true. This is not a study, as I see it, it is just for fun.